课程名称:2.1 When to use TiDB platform(TiDB 的适用场景)
学习时长:30min
课程收获:
本节课程主要介绍了 TiDB 的一些典型使用场景,介绍了 TiDB 在 OLTP 类型的场景中使用,在实时 HTAP 场景中的使用,借助 TiSpark 使 Spark 能够读取 TiDB 的数据,进一步加强数据整合以及TiDB 不适用的场景。
课程内容:
学习目标: 熟悉 TiDB 的一些典型使用场景,并且能大致的判断哪些场景适合 TiDB,哪些不适合
关键知识点: OLTP 场景;实时分析数据库; Spark
OLTP场景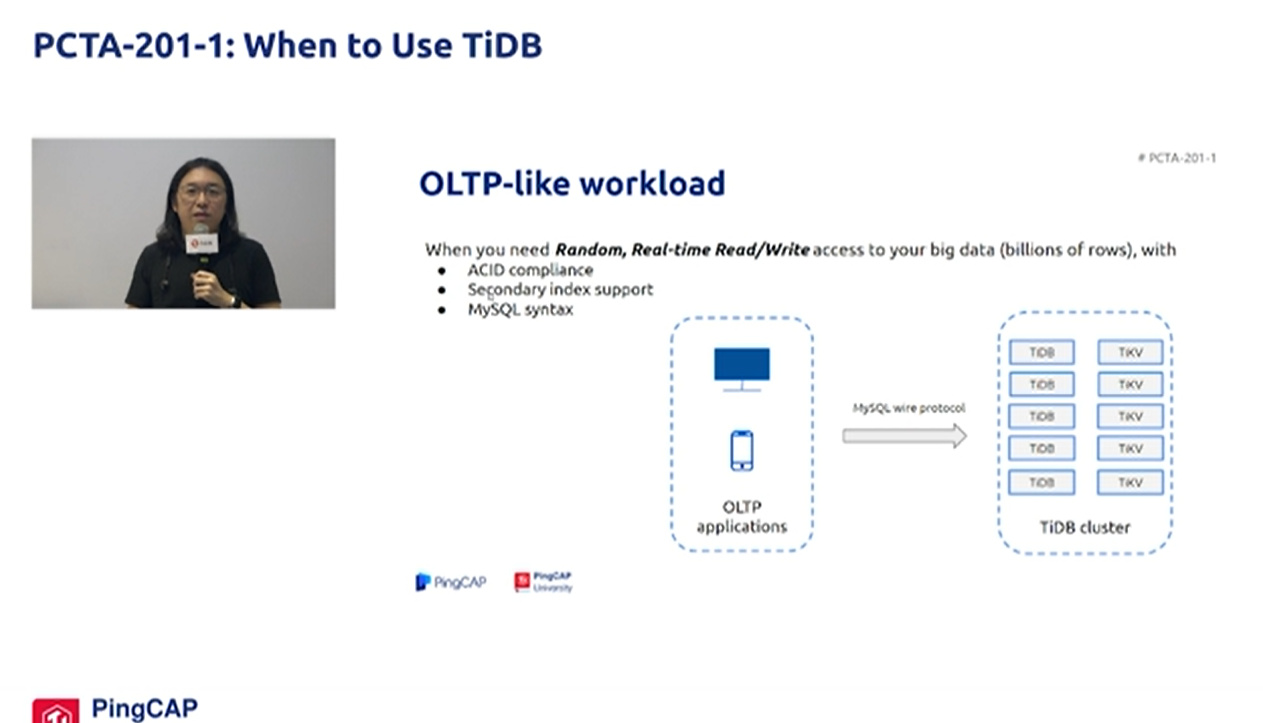
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。得益于 TiDB 存储计算分离的架构的设计,可按需对计算、存储分别进行在线扩容或者缩容,扩容或者缩容过程中对应用运维人员透明。
随着业务的高速发展,数据呈现爆炸性的增长,传统的单机数据库无法满足因数据爆炸性的增长对数据库的容量要求,可行方案是采用分库分表的中间件产品或者 NewSQL 数据库替代、采用高端的存储设备等,其中性价比最大的是 NewSQL 数据库,例如:TiDB。TiDB 采用计算、存储分离的架构,可对计算、存储分别进行扩容和缩容,计算最大支持 512 节点,每个节点最大支持 1000 并发,集群容量最大支持 PB 级别。
数据访问最好是均匀的,小范围热点数据使用要特别注意。
支持建立二级索引,海量数据量级上保证毫秒级延迟。
相对于NoSQL,就像使用传统SQL数据库一样,支持SQL语法。
相对于MySQL分库分表扩展方案,TiDB提供更全的功能,业务最小的改动。
Real-time HTAP 场景
Real-time HTAP 场景
TiDB 在 4.0 版本中引入列存储引擎 TiFlash 结合行存储引擎 TiKV 构建真正的 HTAP 数据库,在增加少量存储成本的情况下,可以同一个系统中做联机交易处理、实时数据分析,极大地节省企业的成本。
数据汇聚、二次加工处理的场景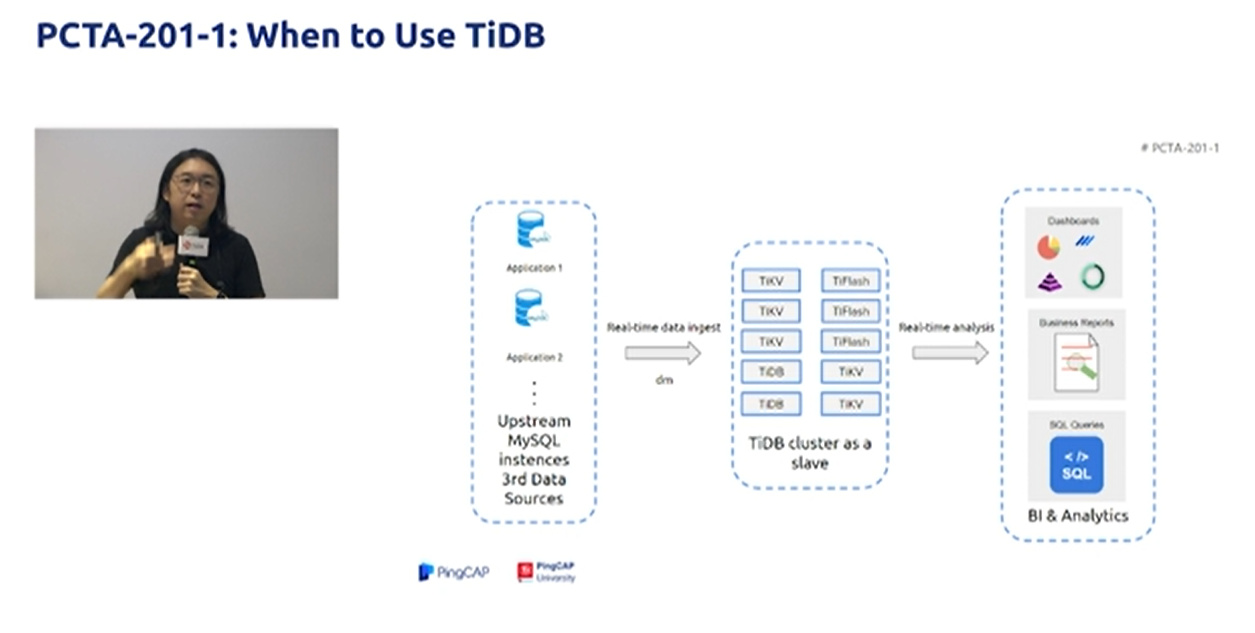
当前绝大部分企业的业务数据都分散在不同的系统中,没有一个统一的汇总,随着业务的发展,企业的决策层需要了解整个公司的业务状况以便及时做出决策,故需要将分散在各个系统的数据汇聚在同一个系统并进行二次加工处理生成 T+0 或 T+1 的报表。传统常见的解决方案是采用 ETL + Hadoop 来完成,但 Hadoop 体系太复杂,运维、存储成本太高无法满足用户的需求。与 Hadoop 相比,TiDB 就简单得多,业务通过 ETL 工具或者 TiDB 的同步工具将数据同步到 TiDB,在 TiDB 中可通过 SQL 直接生成报表。
使用Spark打通TiDB和其他大数据平台
TiDB令Spark直接读取TiDB的数据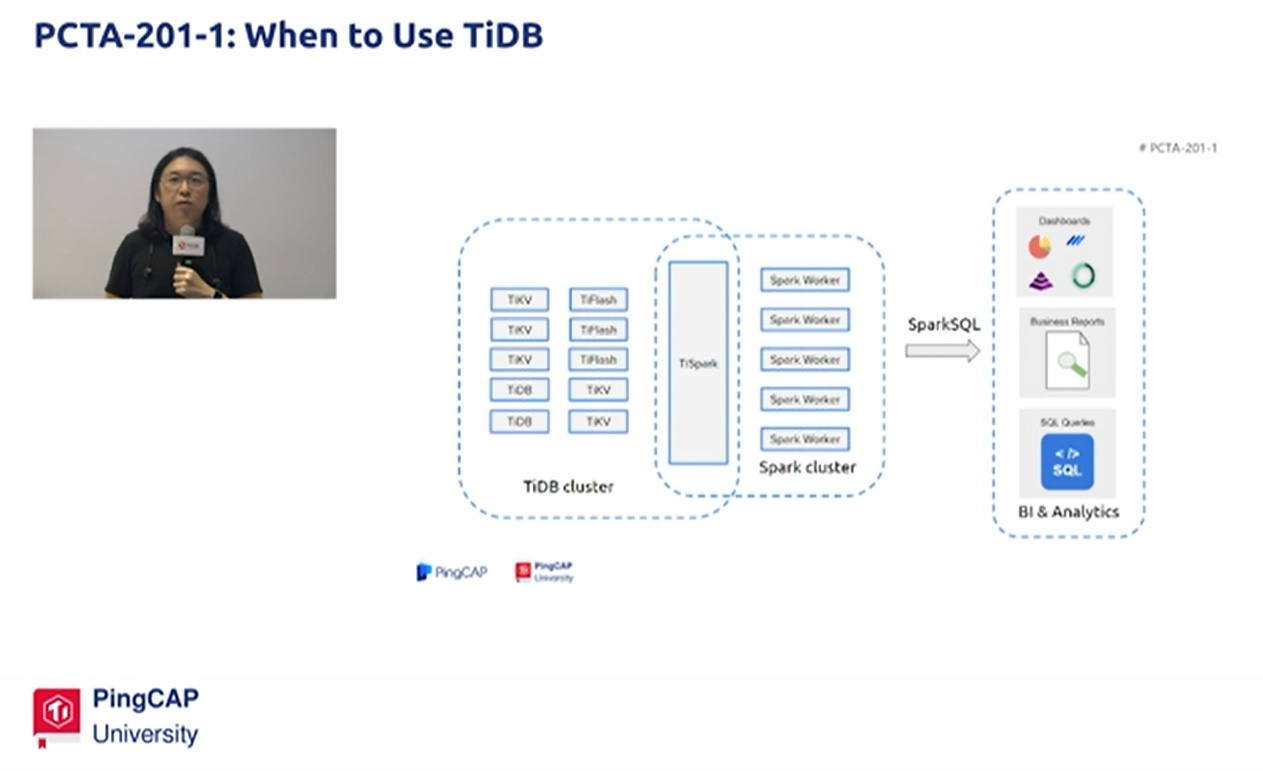
TiDB不适合的场景
数据能够运行在单机服务器中
业务中需要重度的分析场景
OLTP场景要亚MS级别延迟
总结
学习过程中参考的其他资料
- [TiDB 的适用场景视频教程](https://university.pingcap.com/courses/TiDB 4.0 应用开发指南/chapter/201-章节/lesson/When-to-use-TiDB-platform)
- TiDB 简介


